The Java Standardization Request 168 (JSR 168) defines a portlet specification, including a contract between the portlet container and the portlet. JSR 168 is defined by the Java Community Process (JCP). The JSR 168 was co-led by IBM and Sun and had a large Expert Group that helped to create the final version which is now available. This Expert Group consisted of Apache Software Foundation, Art Technology Group Inc.(ATG), BEA, Boeing, Borland, Citrix Systems, Fujitsu, Hitachi, IBM, Novell, Oracle, SAP, SAS Institute, Sun, Sybase, Tibco, Vignette. More details about this JSR can be found at http://jcp.org/en/jsr/detail?id=168.
Important: The information provided in this analysis is provided without warranty of any kind. The analysis is intended to be an informational tool only for the reader.
JSR 168 definitions
This section provides basic JSR 168 definitions so that you can understand how JSR 168 fits into the overall portal architecture.
Portal and portlet container
A portal is a Web application which typically provides personalization, single sign-on, content aggregation from different sources, and hosts the presentation layer of different backend systems.
The main task of a portal is to aggregate different applications into one page with a common look and feel for the portal user. A portal may also have sophisticated personalization features which provide customized content to users. Portal pages may have different sets of portlets to create content for different users.

depicts the basic architecture of portals, such as a portal that is served by WebSphere Portal. A client request is processed by the portal Web application, which retrieves the portlets on the current page for the current user. The portal Web application then calls the portlet container for each portlet to retrieve its content through the Container Invoker API. The portlet container calls the portlets through the Portlet API. The Container Provider Service Provider Interface (SPI) enables the portlet container to retrieve information from the portal.
The portlet container runs the portlets, provides them with the required runtime environment, and manages their lifecycle. It provides persistent storage for portlet preferences which enables the portlet to produce customized output for different users.
Portal page and portlets

depicts the basic portal page components. The portal page represents a complete markup document and aggregates several portlet windows; that is, it combines different application user interfaces into one unified presentation. The portal page lets the user authenticate to the portal through the login dialog to access a personalized portal view. Most portal pages include some navigation mechanism to enable the user to navigate to other portal pages.
A portlet window consists of:
- Title bar, with the title of the portlet
- Decorations, including buttons to change the window state of the portlet (such as maximize or minimize the portlet) and buttons to change the mode of a portlet (such as show help or edit the predefined portlet settings)
- Content produced by the portlet (also called a markup fragment).
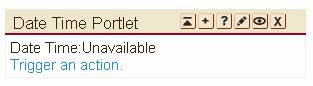
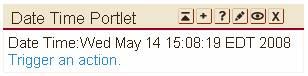
 Figure 3 shows such a portlet window on different browsers. As you can see, the markup fragment produced by the portlet is not restricted to HTML, but can be any markup.
Figure 3 shows such a portlet window on different browsers. As you can see, the markup fragment produced by the portlet is not restricted to HTML, but can be any markup.
Portlet lifecycle
The basic portlet lifecycle is to:
- Initialize, using the init class to initialize the portlet and put it into service.
- Handle requests, processing different kinds of actions and rendering content.
- Complete, using the destroy class to take the portlet out of
The portlet receives requests based on the user interaction with the portlet or portal page. The request processing is divided into two phases:
- Action processing
If a user clicks on a link on the portlet, an action is triggered. The action processing must be finished before any rendering of the portlets on the page is started. In the action phase the portlet can change the state of the portlet.
- Rendering content
In the render phase, the portlet produces its markup to be sent back to the client. Rendering should not change any state. It allows a page re-fresh without modifying the portlet state. Rendering of all portlets on a page can be performed in parallel.
 Figure 4 depicts the request flow from the client to the portlets, and shows the action and render phases in more detail. In this example, portlet A has received an action. After the action is processed, the render methods of all portlets on the page (A, B, C) are called.
Figure 4 depicts the request flow from the client to the portlets, and shows the action and render phases in more detail. In this example, portlet A has received an action. After the action is processed, the render methods of all portlets on the page (A, B, C) are called.
Portlet modes
Portlets perform different tasks and create content according to their current function. A portlet mode indicates the function a portlet is performing, at a point in time. A portlet mode specifies the kind of task the portlet should perform and what content it should generate. When invoking a portlet, the portlet container provides the mode for the current request to the portlet. Portlets can programmatically change their portlet mode while processing an action request.
JSR 168 defines three categories of portlet modes.
- Modes which are required to support (same semantic as above)
Edit
Display one or more views that let the user personalize portlet settings.Help
Help
Display help views.
View
Display the portlet output.
- Optional custom modes
About
Display the portlets purpose, origin, version, and other information.
Config
Display one or more configuration views that let administrators configure portlet settings which are valid for all users.
Edit_defaults
Set the default values for the modifiable preferences that are typically changed in the EDIT screen.
Preview
Render output without the need to have back-end connections or user specific data available.
Print
Display a view which is suitable for printing.
- Portal vendor specific modes
These modes are only available in a specific vendor portal.
Window states
A window state is an indicator of the amount of portal page space assigned to the content generated by a portlet. The portlet container provides the current window state to the portlet, and the portlet uses the window state to decide how much information it should render. However, portlets can also programmatically change their window state while processing an action request.
JSR 168 defines the following window states:
Normal
The portlet shares the space with other portlets and should take this into account when producing its output.
Maximized
A window has more real estate to render its output than in normal window state.
Minimized
The portlet should only render minimal or no output.
In addition to these window states, JSR 168 allows the portal to define custom window states.
Data model
JSR 168 defines different mechanisms for the portlet to access transient and persistent data.
The portlet can set and get transient data in the following scopes:
Request | The request has attached data, such as request parameters and attributes, similar to the servlet request. The request can contain properties to allow extension, and client header fields being transported from the portal to the portlet and vice versa. |
Session | The portlet can store data in the session with either global scope, to let other components of this Web application access the data, or portlet scope, which is private to the portlet. |
Context | The portlet can store data in the Web application context, similar to servlets |
The portlet can access persistent data with these scopes:
Per portlet | The portlet can store configuration and personalization data in the portlet preferences to enable the portlet to create personalized output. The portlet can define which data the user is allowed to change in the edit mode (for example, stock quotes), and which data are configuration settings can only be changed by an administrator in config mode (for example, the stock quote server). |
Per user | User profile information can be read by the portlet to tailor its output towards the user (for example, show the weather of the city where the user lives). |
Portlet application
All resources, portlets, and deployment descriptors are packaged together into one Web application archive (WAR) file. There are two deployment descriptors:
- All Web application resources that are not portlets must be specified in the web.xml deployment descriptor.
- All portlets and portlet related settings must be specified in the portlet.xml deployment descriptor.